

Lattice has been working on MUD for almost two years. Within those years, we’ve packed in two versions of MUD, three games, millions of entities, and uncountable engineering hours. With the completion of MUD v2, and a soon-to-be finished audit by Open Zeppelin, we wanted to take a look back and share how we got here. What made us so hell-bent on creating a framework that developers could use to create ambitious applications? What were the discoveries, challenges, and breakthroughs we encountered along the way? And what do we have planned next for MUD, to continue our mission of pushing the envelope of EVM applications?
Read on to learn more.
Signs From the Universe
The year is 2021 and onchain gaming is in its infancy. The success of Dark Forest has proven that there is demand for fully moddable and extensible worlds, which can live autonomously and exist without the iron hand of an administrator. The game has a small but ardent player base, dozens of user-built plugins, and has inspired the creation of user-coordinated guilds and alliances. The code is open-source; the gods of autonomy are pleased.
What is less clear is how someone might try to build the next Dark Forest. Or any onchain game for that matter. If you examined the Dark Forest codebase you’d find an approach that worked well for the game, but didn’t lend itself to easy abstractions. The format used by Dark Forest was:
- Structs for types of things in the game (ie
Planet,Player, …) - mappings for each struct (and arrays to keep track of the keys)
- getter functions for each type of storage
- and events whenever any of the data changed (
PlanetInitialized,PlanetUpgraded, etc) - Similar custom data structures on the client (
Planetsetc) with manual loading of initial state and custom “reducers” to listen to thePlanetInitialized, PlatetUpgradedetc events
It was organized, sure. But it was custom, and provided no simple framework for other games to reference.
On the networking side, there were scalability issues. To access the game state from the contracts, Dark Forest core developers used getter functions, which couldn’t be cached by the RPC. This was therefore very expensive on the RPC for xDai. The RPC costs were in the tens of thousands of dollars when a Dark Forest round was running.
At the time, these were just facts of life: accepted struggles of designing games for the EVM. There were no neat frameworks, and no cheat codes. Everything was custom.
Inspired by Dark Forest, we decided to build a new game — a cross between a board game and a battle royale called ZKDungeon. In retrospect, it was perhaps an overly ambitious undertaking. ZKDungeon used the same approach as Dark Forest, but we quickly realized that most of the time developing the game was spent on changing the network stack (updating structs, updating events, updating event processing logic on the client). It was a demanding and unwieldy process, which made it hard to iterate on the game. We implemented the Diamond Standard, but it was not a panacea: we were still required to update the Diamond storage anytime the contracts were changed.
Looking back, this was a bit of a nightmare. It’s hard to believe that, just a short time ago, this is how developers built games.
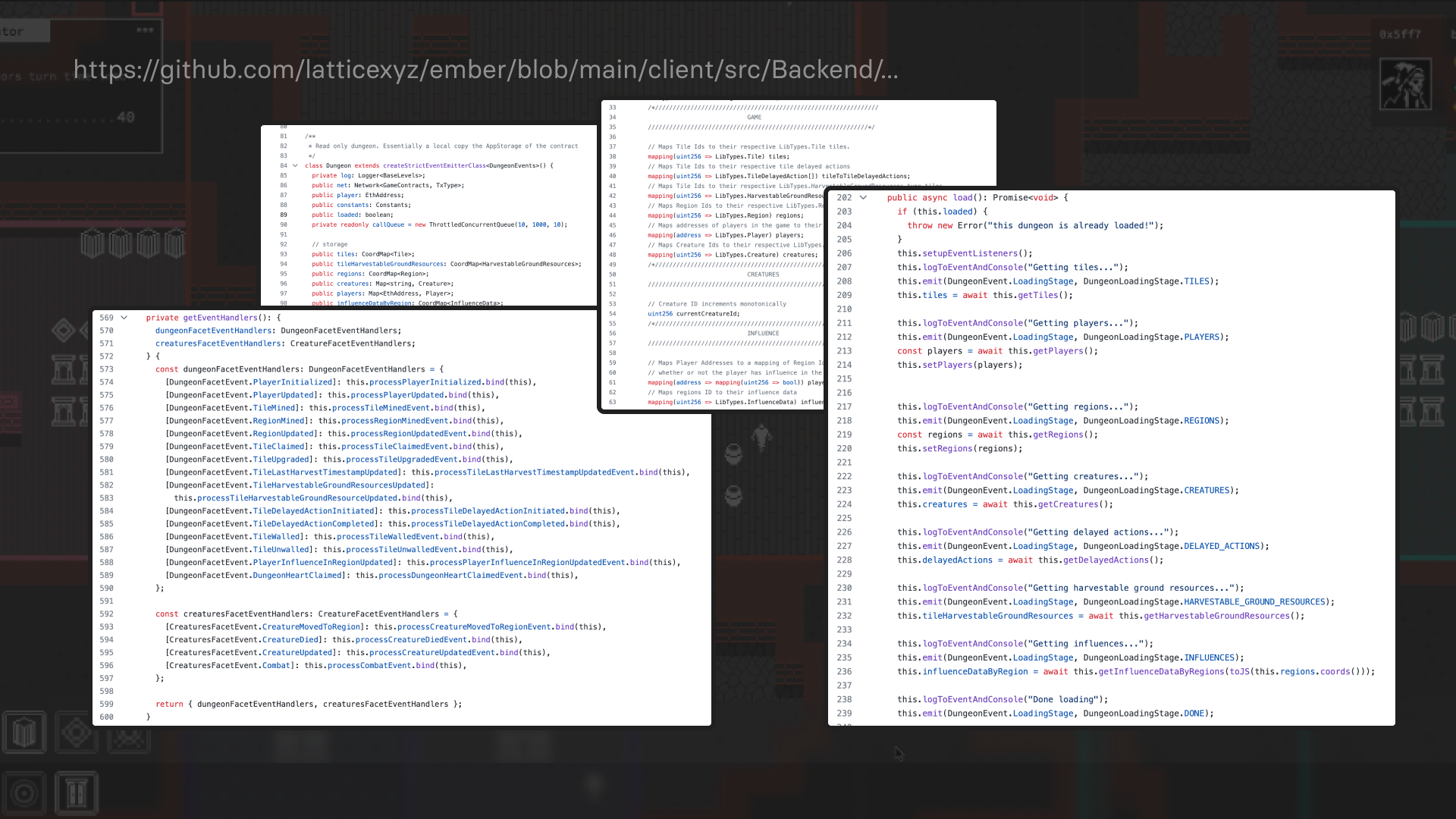
The Origins of MUD v1: Mining For Diamonds
We wanted to live in a world where developers didn’t need to manage synchronization between onchain and offchain state, and where updating application code would be easy for developers. We thought through solutions for how to abstract the problem of state management away from the end developer, and came to the conclusion that we wanted an onchain data structure that automatically emits an event when you update it, which can be used by the client to replicate the onchain state. But how could this be implemented?
Around the same time, we began researching game development more generally, and came across the ECS (Entity Component System) pattern. In the framework, state is stored in Components, logic lives in Systems, Entities are the keys for state in the components, and systems “act on” entities from the components by reading entity “properties”. It seemed like an abstraction that would ease a lot of the pain we were seeing in our custom-made logic. It also seemed like a good approach to separate logic into separate contracts, and separate logic from state, as it would be a sort of “in-protocol” Diamond Standard.
No one else was using ECS onchain at the time, so it was a bit of a gamble. There was also no clear roadmap on how to implement ECS in Solidity, so we had to think from first principles to determine how to achieve this.
First, we needed an event that has the same signature for any type of state. In other words, we had to remove the types from the state updates and have a common umbrella type. The common denominator of all types is “bytes”, which is essentially “untyped” data. So we knew our update events have to use “bytes” for state.
But how do you turn your custom type into bytes while still being able to decode it later? Solidity has a primitive called “ABI encoding”, so by using abi.encode you can turn almost anything into a blob of bytes. If you know the type, you can use abi.decode to turn it back into its original form. We used this mechanism to implement “components”, the place to store data.
Each component was its own contract that implemented an interface with setters and getters for state. Internally it emitted the event as bytes, and stored the raw ABI encoded bytes in storage. Then we stored the type of each component in another component, and used it to decode the state on the client. Systems were their own contracts too. The indexer could listen to all of these events, decode the data, and store it in a database.
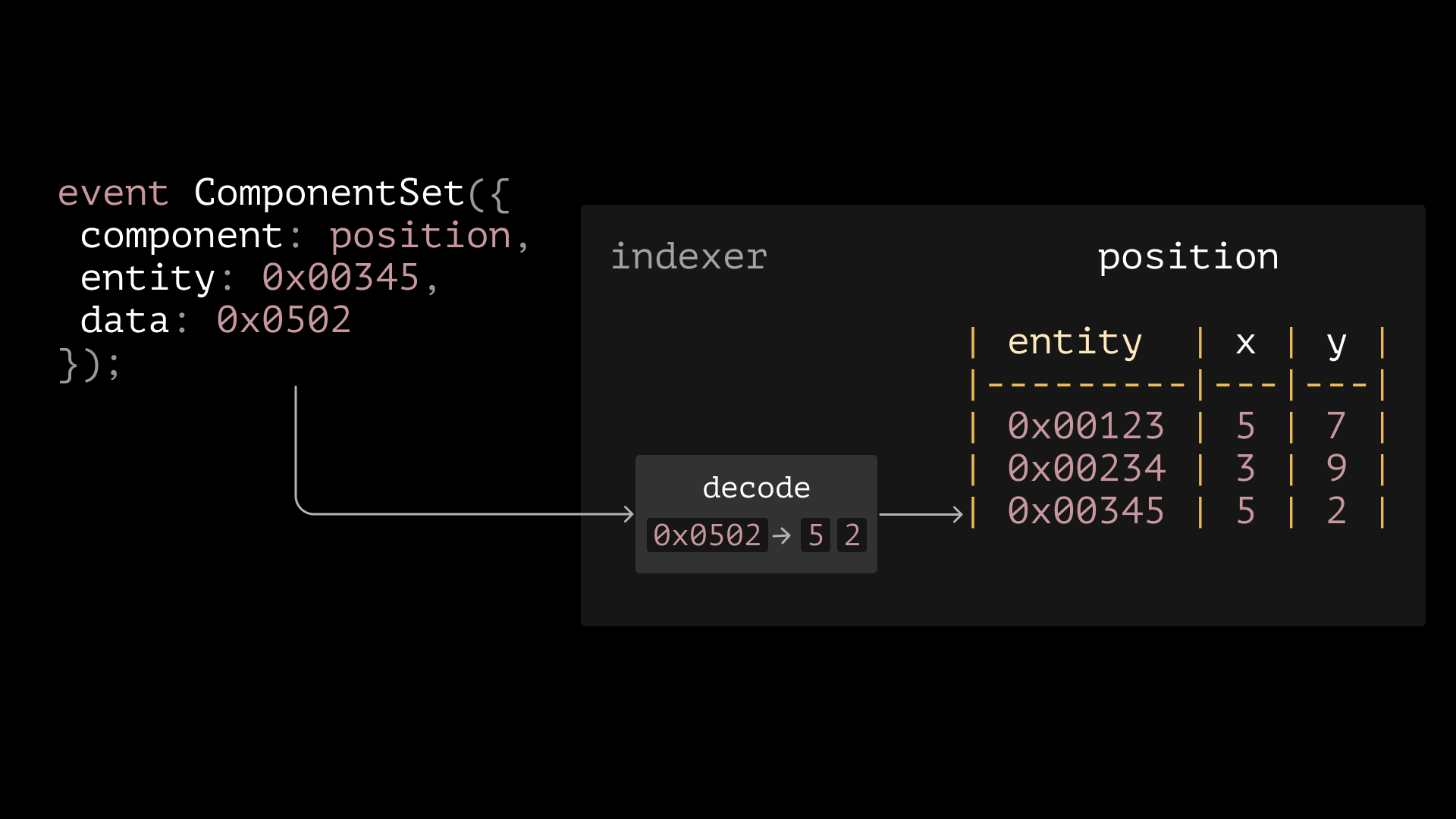
There was a central contract tying it all together, which we called “World” (a term common in ECS for the “global state”). The systems would get the address of the components they cared about from the component registry in the world, and then read and write the state on the components. Each component had its own access control for who can write to them.
Every time a component was updated, it registered the state update in the central World contract, which emitted an event that could be used by offchain indexers to replicate the state. This meant no more contracts with idiosyncratic event emissions, and no custom networking code to ensure these events could be read externally, either in the client or on indexing tools like The Graph.
This approach worked - it allowed us to iterate much faster than before. And the approach is what eventually became MUD v1.
Just how fast was development? To test out MUD v1, we decided to build a game inspired by Minecraft, which we called OPCraft. The initial proof-of-concept took us just two days to design, enabled by the ECS framework and engine we had designed. The ECS design primitives were as follows:
- every block was an entity that had a
TerrainTypeandPositioncomponent attached to them - when mined the
Positioncomponent is removed and anOwnedBycomponent is added instead. This made the codebase super simple.
We then spent three more months going from prototype to the final polished product. This involved adding a perlin noise implementation in Soldity and WebAssembly to procedurally render the terrain before blocks were mined, and other improvements, like a way to “randomly” place diamonds in the map, and overall updates to graphics, sound effects, and controls.
We also added an offchain peer-to-peer broadcasting mechanism for player positions, and a mechanic for claiming a chunk to protect it from other players based on who staked the most diamonds in the chunk (this mechanic was later used by an unknown user to create the Autonomous People’s Republic of OPCraft). The emergent behavior we saw in OPCraft proved out another theory we had about MUD: not only was it useful for first-party developers building ambitious applications, but its abstractions also lent itself easily to third-party developers building plugins and mods.
We launched OPCraft on the one of the first Optimism Bedrock testnets during Devcon in 2022. We aimed for a two week playtest, the goal of which was a tech demo and hardening of MUD v1. While the playtest went successfully (see these three blog posts for more detail), we ran into one big issue: state bloat. By the end of the playtest, it took around 20 minutes to load the client state, and that was even with an indexer (rather than loading directly from the RPC blockchain node). This was partially caused by OPCraft architecture (using unique entities for each block instead of just a number per block type per player), and partially by MUD1’s naive and inefficient data encoding (abi.encode). Things could be better.
So we went back to the terminal. We knew we weren’t done developing MUD yet.

From MUD v1 to MUD v2: Back to the Skies
MUD v2 to emerged to solve three major problems: our approach to data encoding, our MUD-native data model, and the limitations of the ECS model. In early 2023, alvarius laid these problems out two now-iconic Github issues, one on data modeling and the other on the World framework.
As mentioned in the section above, the abi.encode method in MUD v1 was naive and inefficient. It used a lot of padding (it took 32 bytes for every value, independent of data size, and added another 32 bytes for metadata), so the data emitted in events and stored in storage was sub-optimal.
For MUD v2, we improved a number of things: we implemented more efficient data encoding, that doesn’t add unnecessary padding to onchain storage and events. We also developed a more advanced indexer that stores data in its tightly packed form instead of in its padded form (which helped alleviate state bloat).
But there were other limitations that had to be overcome. The ECS model limited developers to single primary keys in a database, and was familiar only to people with a gaming background, rather than a general audience of developers who are familiar with relational databases. The data model in MUD v1 was such that the Entity ID was the primary key, which had components associated with it. But in a relational database (like Postgres), you can have tables where multiple columns are the key (e.g. a combination of multiple keys can uniquely identify a row). We wanted MUD v2 to represent data in a more general way, with support for multiple key-values (as you would get in any traditional relational database).
We were able to achieve very efficient and tight bitpacking of data stored in tables.
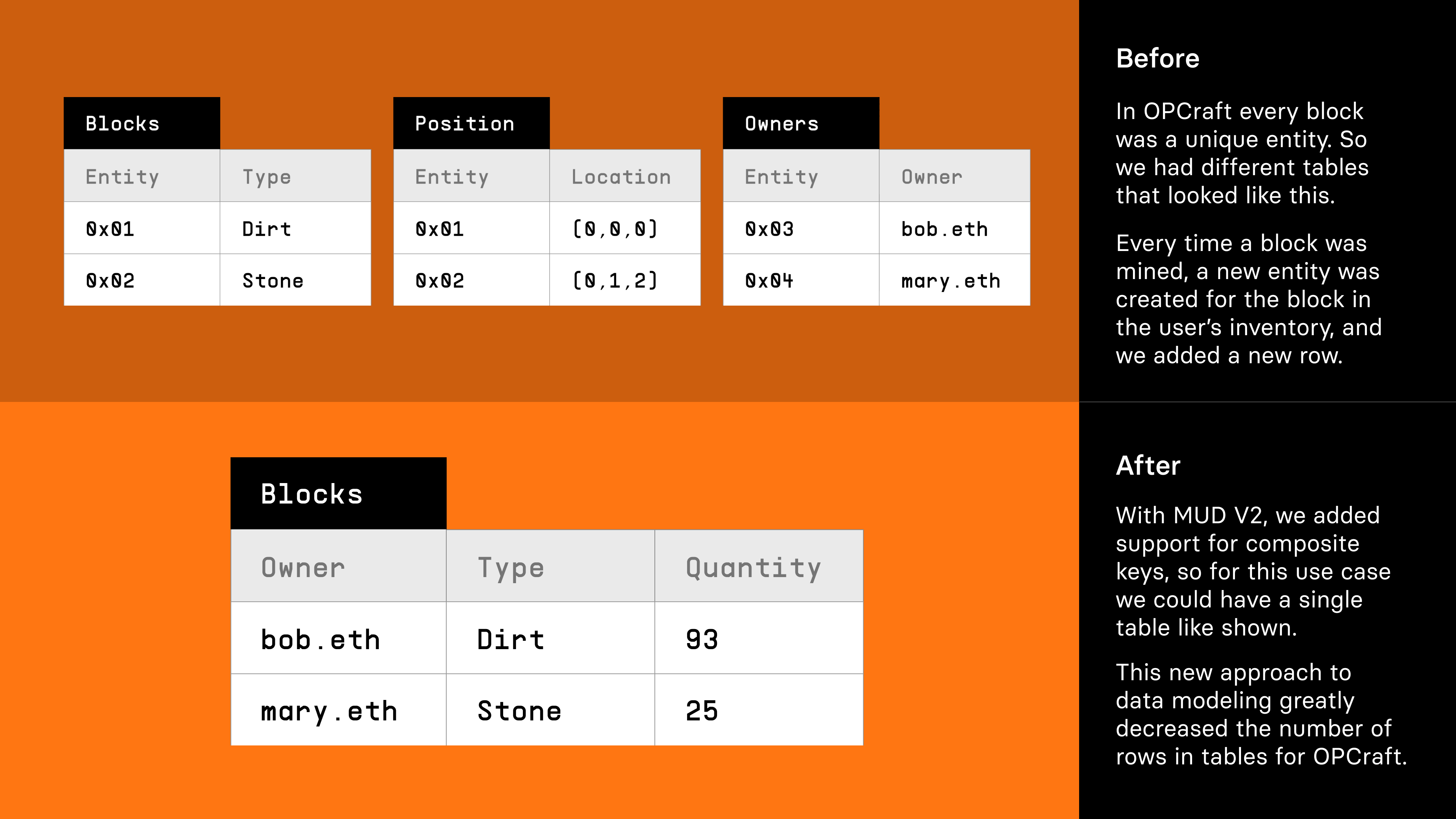
This means the addition of multiple key values in MUD2 would allow us to architect OPCraft in a way that would bring down the number of rows in the tables from about 3x total number of blocks (three tables and one row per block per table) to about number of users x types of blocks (which is 0.06% of the original number of tables, given there were around 10 million blocks mined in OPCraft, but only around 2k players and around 10 block types). This kind of data modeling in MUD v2 paved the way for development on our next game, Sky Strife.
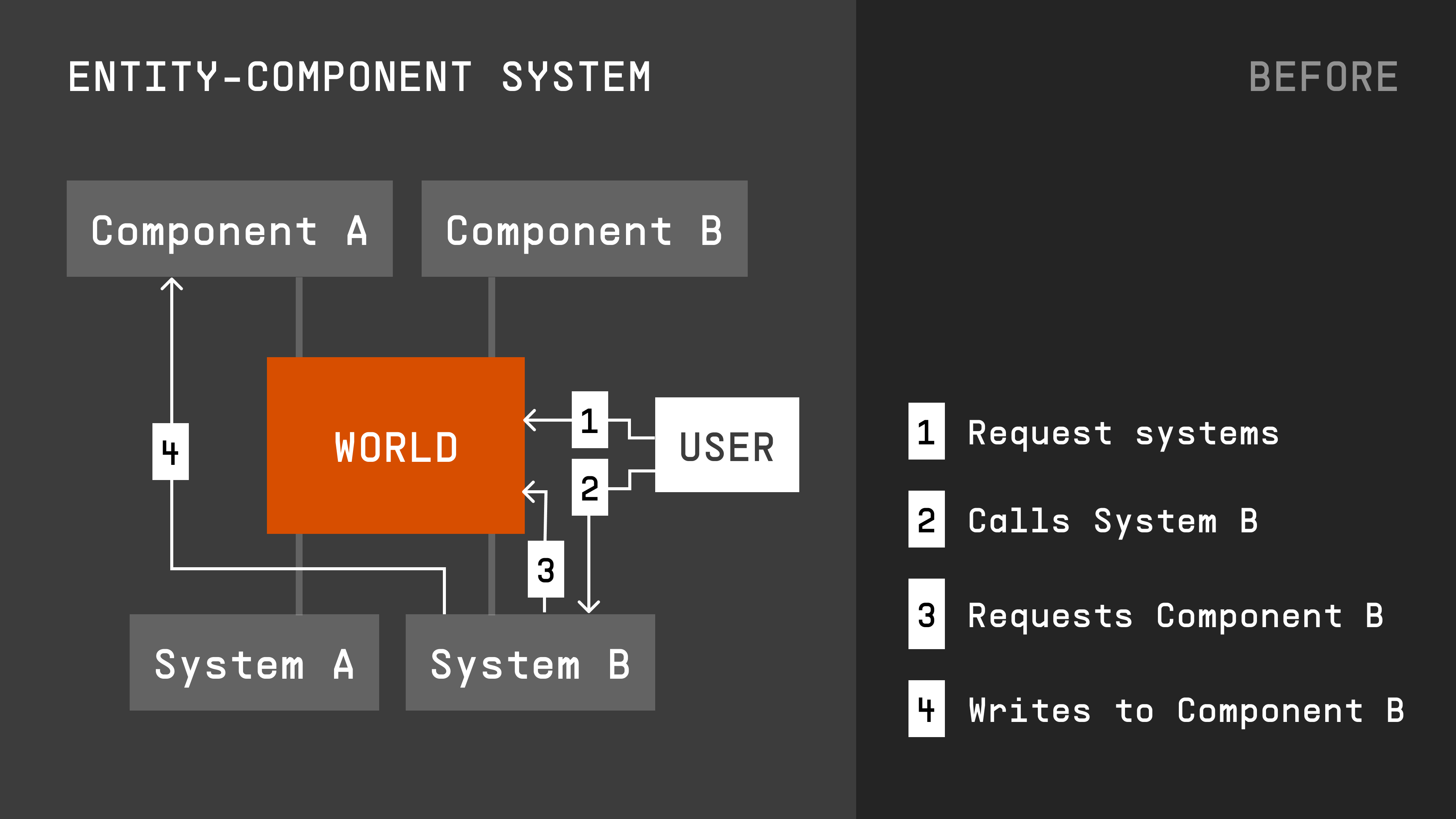
Additionally, in v1 each component was its own contract, systems were called directly by the client, and there was no central place to put shared logic (like access control or features like account delegation). We wanted to abstract all of that away; the only thing developers should care about is the type of data they’re working with. They should be able to define data in a config, and generate Solidity libraries that interact with data. To do this, we implemented a central storage engine.
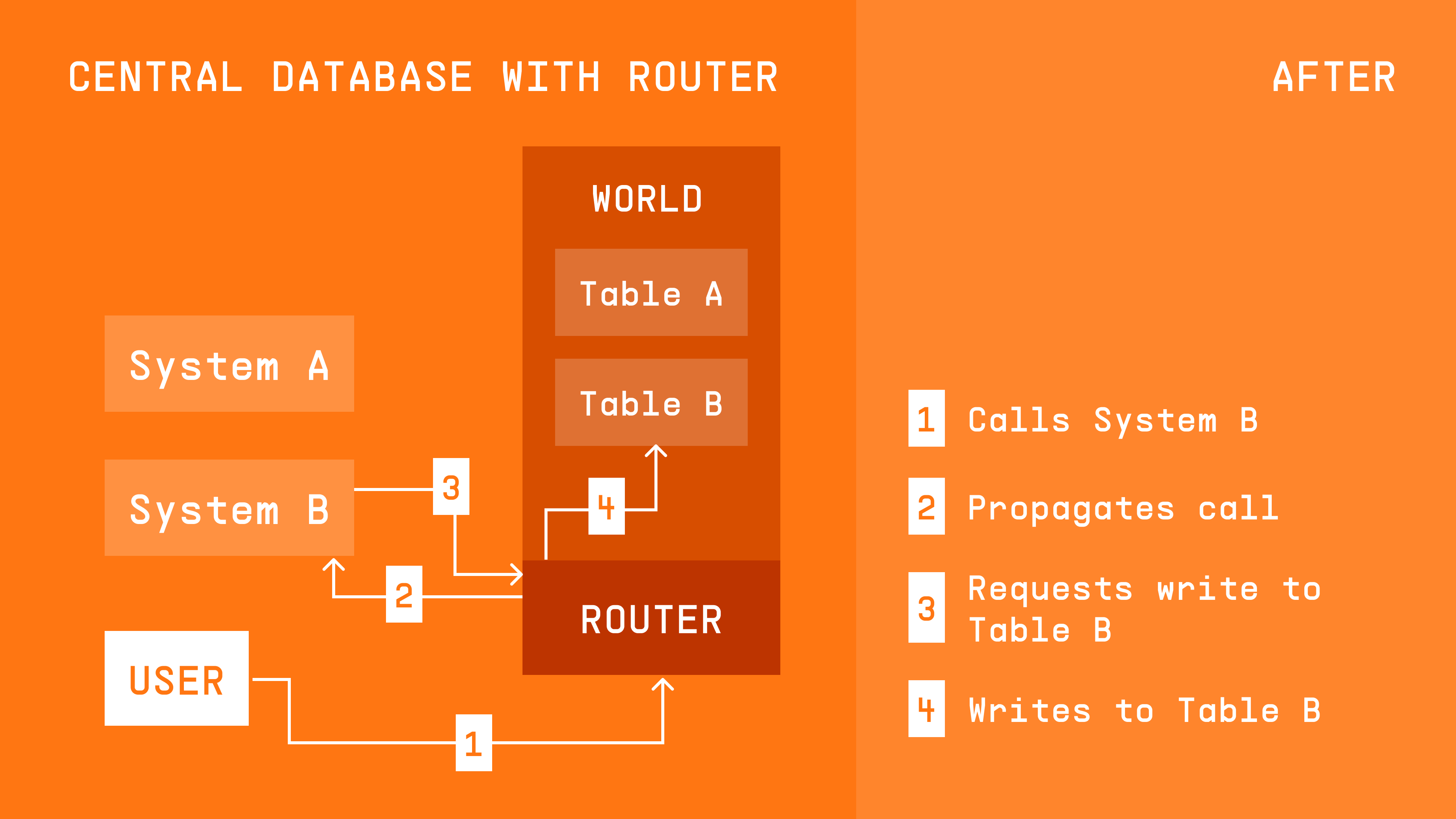
The central storage engine unlocked a number of things: it improved the developer experience, and opened the path for capabilities like account delegation or storage hooks, which happens one level above the systems. Before, developers would’ve had to create account delegation logic for each system, because each system is called separately. Instead, everything is now managed by the central World contract.
The development of Sky Strife, and the needs illuminated by the game, brought further upgrades to MUD. One example of this is in MUD’s capability of segmenting state. Sky Strife matches exist for a short amount of time — only about fifteen minutes — and many run at the same time. It would be expensive and inefficient if your client had to load the state of all matches, rather than just the one that any player is engaged in at a particular time To permit this, MUD worlds can now use a composite key to define segments of state, and both the indexer and client can ignore the keys that your client is not concerned with. This is open to all MUD developers out of the box, though it originated as a need for scaling Sky Strife and OPCraft.
With improved data encoding, a more database-friendly data model, and a move from ECS to the full power of relational databases, the updates to MUD v2 were complete. In September, we selected Open Zeppelin as our auditor for MUD v2, and are in the process of having the contracts and code-generated libraries audited.
What’s Next?
On the horizon, we’re excited about Modules, which are bundles of tables, systems and other resources that can be installed into existing deployed Worlds and extend them with new functionality. Modules can be developed and deployed once, then be installed in an arbitrary number of Worlds. We’re planning to have an onchain registry of modules, kind of like npm, but for MUD Worlds. In Ethereum there are lots of libraries that are shared (Open Zeppelin libraries, for example). But there’s no “package manager” and everyone redeploys the same libraries specifically for their own projects. With modules, you only have to implement them once, and then are able to deploy them throughout any possible existing World.
Dozens of teams are building with MUD, and after the v2 audit is complete, we can officially recommend its usage in Mainnet deployments. This is especially exciting given our recent announcement of Redstone - a super cost-effective chain for games and worlds. As we reach a wider audience, we’ll continue to improve the framework, and push the envelope of Ethereum applications. We’re excited to see the next era of onchain applications and autonomous worlds begin.
We would like to thank the teams building on MUD, developers who have submitted feedback on Discord and in person, and all contributors to the MUD codebase for making our work possible.