

For this special installment of Devs on Devs, we brought together tdot, the core protocol developer of Plasma Mode (and by extension, Redstone), and Ben Jones, a co-founder of Optimism, the collective behind the OP Stack. Plasma Mode allows developers to build on the OP Stack, but instead of posting data to L1, there is flexibility in switching to an offchain data provider, leading to cost savings and scalability. In this conversation, they explore the origins of Redstone’s and Optimism’s collaboration, reviving Plasma from the dead, the importance of bringing experimental protocols into production, future roadmaps for Plasma Mode and the OP Stack, and their excitement to see the onchain gaming space evolve.
Modding the OP Stack with Plasma Mode
Ben: What was the journey of embarking on an OP Stack improvement like?
tdot: I joined Lattice about a year ago just to work on Plasma Mode. There was a clear goal. We had all these MUD apps and they were consuming a lot of gas and we were trying to put so much data onchain. So we needed something that could support that and be cheap at the same time. The Lattice team had already been playing with the OP Stack a little bit, just like prototyping some of the first on-chain worlds and deploying them on the OP Stack. We noticed that the OP Stack was already really good.
So then we asked ourselves, “Okay, how do we make it cheaper?” Generally the whole assumption was, “We think the OP stack is just the most Ethereum aligned, and fully EVM compatible framework.” You run something on mainnet, and it runs on the OP stack the same way. It was really the ideal solution. But then we obviously wanted to make it even cheaper.
Bear in mind, this was at a time where calldata was still the DA source for OP stack chains, and that was pretty expensive at this time. So we obviously were not able to bootstrap an L2 chain with calldata, knowing the throughput that we wanted for our onchain games and MUD worlds. So that's why we're decided that we're going to start experimenting with Alt DA. In fact, in the first OP Stack docs, there were already these side quests which said, “Go explore this topic or go explore this other thing, and one of them was Alt DA.
From there, we asked, “What does it look like if you start with DA that’s offchain?” We really wanted to keep the whole security model and everything on L1 Ethereum. And so that's why we kind of shied away from other Alt DA solutions, and decided to store data on centralized DA storage, and then figure out a security model that worked on L1.
That's how we reuse some of the old Plasma concepts and put it on top of the rollup stack. So obviously, there were some differences there. The big question was, how do we implement offchain DA and onchain data challenges with the existing OP Stack? The whole idea was that we would have as few diffs as possible with the OP Stack and no changes to the rollup path, because we don't want to affect the security of the other rollup chains that are using the OP Stack.
When you're designing a rollup, you're not thinking, “Oh, what happens if someone changes the derivation pipeline to store data from somewhere else?” So even with these changes we made, the OP Stack was still very robust and worked really nicely out of the box. And those were the first changes that we made.
After that, we needed to write contracts that could create these challenges. There are DA challenges for forcing the data to be onchain. So that was the second step, integrating the contracts inside the pipeline. We had to build this whole integration inside of the derivation so you could basically derive it from an offchain DA source and as well from an L1 DA challenge contract in case the data is submitted onchain during a challenge that is resolved.
So that was the gist of it. It was complicated because you wanted to keep things elegant and robust. At the same time, it's a pretty simple concept. And we didn't go and try to reinvent everything or change the whole OP Stack or anything like that. We were really trying to keep things simple in a very complex environment. So overall, it was a really cool engineering journey.
Ben: I can speak from the OP perspective. You mentioned some of the early work that Lattice did. For what it's worth, the timing was quite impeccable because at the same time that you guys were embarking on that journey, at Optimism we were basically undergoing almost an end-to-end rewrite of the entire OP Stack, which was this release that we called Bedrock.
Basically after two years of building this rollup stuff, we took a step back and said, “Okay, if we were going to do this really, really, really well with all the lessons that we had learned, what would that look like?” And that evolved into the codebase that ended up becoming known as Bedrock, which was basically the biggest upgrade that we ever did to the network.
Around that time we worked with you guys on what was called OPCraft, which I think Biomes is a spiritual successor of, which was the most fun that we’d had onchain in a very long time. We also had a massive sigh of relief that other people could do things with the OP Stack. I think one of the other transition points for scaling in general that's occurred over the last couple of years is basically getting to the point where many people can run chains.
 Karl Floersch, co-founder of Optimism and CEO of OP Labs, observes OPCraft gameplay with the Lattice team in 2022.
Karl Floersch, co-founder of Optimism and CEO of OP Labs, observes OPCraft gameplay with the Lattice team in 2022.
And it's not just the people who built some monstrous Frankenstein codebase that should be able to do that. So when we started working together, it was just incredible validation that somebody else can come along and take this codebase and do something really amazing with it. It was really cool to then see that extend to Plasma in practice. And I can even ramble a little bit about the history there.
Before Optimism was known as Optimism, we were actually working on a thing called Plasma. What we were effectively doing there was taking on a much larger bite than was reasonable for the scaling community to chew at the time. And the designs that you would see in the early Plasma days may not have a direct mapping super intuitively to what we see as Plasma today.
Plasma today is much simpler. We have this separated notion of proving and challenging for state validation, versus challenging for data. Ultimately, the realization we had years ago was that rollups are a much simpler first step than Plasma. I think the community’s takeaway from that at the time was that “Plasma is dead." That was a meme that came out of that period in Ethereum scaling history.
But in the back of our minds, we always thought “Plasma isn’t dead, there's just a smaller bite that we can take off and chew first.” There's a different language that we use now. Like there were these notions back in the day of exits and so on and so forth, which you now can kind of look back and point out and say, “Oh, that was a data availability challenge with some extra steps.” So it's just epic to see that not only the OP Stack being used by others, but being evolved to do some of the stuff that we originally were trying to do but in a very broken and poorly abstracted way. We’ve come full circle, and y'all put super freaking nice abstractions around it and made it work in a way that's reasonable and sane. It's dope to see.
 Coindesk coverage from when Plasma became Optimism
Coindesk coverage from when Plasma became Optimism
It Only Matters If You Ship It
tdot: Plasma Mode has some challenges and open problems that we’re still figuring out. The issue is how do you not work on a 10 year-long timeline? You know what I mean? You want to get to the point where you can ship stuff.
And that's what we were thinking. We already have all these MUD apps that want to be on mainnet now. We needed a mainnet for these games as soon as possible. People were waiting. They were ready for this. You want to have the chain as quickly as possible, to be ready to run, and handle all these apps so that these apps can grow in parallel and become even better while we figure out all these open problems. It takes a long time to get really robust and go from R&D to production stability.
It just takes a lot of time for something to just get onto mainnet and be permissionless and be robust and secure. Seeing the whole loop for how we got there is already crazy. That's why I feel like we need to be super agile as well because there's just so much. The ecosystem is moving so fast. I think everybody's just shipping tons of innovations. That's why you have to keep up. But you also can't trade off on security and performance, because otherwise things just don't run.
Ben: Or just technical debt. You alluded to the small diff thing; that was a core tenet, basically, when we were doing that Bedrock rewrite. I talked about this end to end rewrite, but more importantly, we had something like 50,000 line reduction in the codebase, which itself is super powerful. Because you're right, these things are hard.
And every line of code that you add is going to take you further from production, make it harder to get things battle tested, and introduce more opportunities for bugs. So yeah, we definitely appreciate all the work that y'all did in carrying that torch forward and doing it again for a new mode of operation for the OP Stack.
tdot: The OP Stack really created a way where you can move fast on this kind of thing. Coordinating everyone is so hard when you think about it, because we're obviously two different companies. At Lattice we're building a game, we're building a framework for games, we're building a chain.
You guys are building a hundred things and getting all these things lined up for shipping things on a regular basis. It’s also really crazy in terms of coordination.
Ben: Yeah, definitely a long way to go. But that's modularity to the core, baby. That was definitely, to me, the most exciting thing from the perspective of the OP Stack, like putting aside all of the amazing games and worlds being built on top of Redstone right now. Purely from the OP Stack perspective, this was an incredible example of proof in the pudding, where a lot of awesome core devs have come along and made improvements to the stack, and that's awesome.
This is the first instance where there's a major boolean that you can flip that significantly changes the properties of the system in a major way. Being able to do that thoroughly, there's certainly, to your point, a long way to go. But being able to do that even close to effectively requires modularity, right? And for us, the ability to see you guys do this and not, for example, need to rewrite L2 Geth, is a damn sigh of relief. And to me, it's proof that modularity is working.
tdot: It's getting even better now. I feel like from that example, you're making everything into this kind of own little module that you can tweak and change the property and everything. So definitely curious to see what else gets integrated. I remember one of the things we were nervous about was we had this fork that had all our diffs to the OP Stack and we needed to upstream it. We were like, “Oh my god, this is going to be insane to review everything.”
We had to break it down into small parts, but it just came so naturally. We definitely had really good vibes with the team so it was nice to go through the review process. It felt pretty natural. And I think that it went pretty fast in terms of reviewing and addressing some potential issues. Everything was surprisingly smooth.
Ben: That was really nice. Working on contribution paths to the OP Stack is going to be a big focus for the Collective this year. So I'm super thankful to have you all in the test seat, taking those processes for a drive. I'm glad they weren't overwhelmingly painful and that we got some wins in. And speaking of tdot, I'm curious, what's next for this work from your perspective? What are you excited to be building next?
tdot: There are a bunch of different work streams. The main thread will be integrating with fault proofs. There's a progressive approach to decentralizing the whole stack and increasing the permissionless aspects. And getting to the holy grail of permissionless and forced exits, and things like that.
So we have this endgame in mind, and it's getting there progressively while maintaining security. One of the challenges is, sometimes it's easier to just never ship to mainnet because then you don't have to do hard forks. You're like, “Oh I'll just like wait until everything is fully done” and then you ship it and you don't need to hard fork everything and have tech debt. But if you want to get quickly to mainnet then you have to deal with these complex upgrades and just get in the flow of shipping them frequently. Doing this with high availability is always a challenge.
I think there are a lot of upgrades on the Plasma Mode end that are going to come out after getting fault proofs and all these parts lined up. And then, I think there are still some optimizations in terms of batching commitments together. Right now we're doing it very simply, with one commitment per transaction. A commitment is just a hash of the input data that is stored off chain.
We kept it as simple as possible for the time being, so it was easy and quick to review and there were no big diffs to the OP Stack. But now there are some optimizations there to make it even cheaper if you can do things like batching them together or submitting them into blobs or doing all these different approaches. So we're definitely going to be looking at that as well to reduce the L1 cost.
So that's definitely something we're excited about. And then obviously we're super excited about all the interoperability stuff that's coming up, and being able to cross things between all the chains. Figuring out what that looks like is going to be a huge thing for users.
A lot of this is definitely in your hands for shipping this. But we want to figure out what that looks like on Plasma Mode, and with the different security assumptions.
Ben: Just to speak to that, this will be yet another test of the OP Stack’s modularity. You mentioned fault proofs, obviously we’re super excited for that to ship in Plasma Mode. That's also something that's shipping in the next few months to the roll-ups on Mainnet right now.
One of the great, exciting things about how we've built that codebase is that, with some caveats, it's relatively simple to just hit the recompile button and suddenly be running fault proofs in a new context. So it’s super exciting, I think, to see that in practice, because that will be another example of things just working. As some of the first folks doing that with a massive change, I'm sure it won't be frictionless, but it's definitely a very exciting advantage for the community to actually be able to try that out and launch fault proofs on a significantly changed code base.
tdot: It's really nicely done in a way where you can plug your input in like, “oracle” and just change these data sources inside of the fault-proof pipeline. It shouldn't be too hard. Obviously, you want to make sure that it works on the full end-to-end loop, but I think it shouldn't be too hard to ship as well. That's probably going to be the next thing on the roadmap as well.
Generally, I think we're generally really interested in doing a lot of performance improvements and optimizations. There's not like a magic bullet, you have to go in and figure out tiny things by tiny things by tiny things. If the whole community is just drilling in all these things, it's like an army of devs working on this tirelessly so it's gonna be really nice to progressively get to a very high performance chain on top of amazing stability.
![]()
MUD, Redstone, and Working Together
Ben: I think one of the things that I'm also really excited to see y'all progress on is the integration of MUD and the OP stack. I think there’s a lot of really cool potential. One of the most exciting things that I think we're starting to turn towards in the next year or two is basically carrying the torch of some of the big, huge improvements to performance and throughput that L1 Ethereum has talked about for a very, very, very long time.
The Ethereum research community has made a lot of effort on this, but it's also very high stakes. There are significant changes that require some sort of testbed. The example that I think of here are things like state expiry. There's no question that what y'all are doing is incredible because it pushes the limits of how much incredible stuff can be put onchain. I think one of the things that we're going to see as a result of that is that the “state growth” problem really manifests. This basically means the more games that are played, the more stuff there is that the nodes are keeping track of, and the harder it is for them to execute transactions.
So the Ethereum community has actually known about this for many years and worked on solutions. And I think the things about those solutions that make them tricky is that fundamentally, it kind of changes the structure of how state is managed. You basically have to say, “Okay, at some point, there are these inclusion proofs that you prove so that you can discard the state unless somebody wants to bring it back.”
I'm super pumped because I think MUD is the perfect kind of environment for you guys to be actually implementing those changes and getting them to work. Because you guys already do amazing things with state and you already have a whole framework and model that folks are complying with there. I'm super excited as well, because I think with you guys having a real focus on a framework of how applications are built on Redstone, you're going to be able to do things like experiment with these very tricky things that will have massive performance improvements, but require an update to the paradigm. And I think you guys have the potential to be in the driver's seat to knock those out of the park. So I'm super excited about that.
tdot: That's definitely a good point. I like the idea that MUD can abstract the developer experience of all these kinds of primitives. Basically the OP Stack is bare metal, you're just dealing with the protocol primitives and things like that. And then building with MUD is supposed to abstract away some of these things. When we go to the interop world, we’re looking at what it's going to look like to abstract away over multiple chains and things like that. It's definitely something that we're going to be thinking about with the coupling of MUD and Redstone.
So it's also going to be figuring out what that looks like in an ideal developer experience. It becomes so hard to reason about these matters when you're dealing with all these chains and your users get kind of tired of having to switch between them. If you have tons and tons of L2s at the end of the day you're just gonna get confused. I recently saw people being like, “I just don't remember which chain some of my money is on.” Keeping track of where your balances are on each chain is just so complicated. We're definitely going to need some abstractions for this. Otherwise, it's just going to be really complicated. MUD is definitely a really cool opportunity for this.
Ben: Looking forward to your help. There's definitely a lot of work, but it's super cool.
tdot: I think working with you all was definitely a superpower for us because we're such a tiny team; we're barely 15 people. So obviously tackling all these things is really hard. When you're building on the Superchain and collaborating, all of a sudden you're a giant corporation where you literally have access to all the engineering resources you could need. I was pretty much one of the only engineers at Lattice working on Plasma Mode, but working with Optimism and tapping into all the other core devs multiplies your productivity and then you can like ship stuff that normally would be extremely hard to do by yourself. That flywheel is extremely cool.
It felt really powerful when I experienced it. I was like, “Wow, I can't believe we just shipped that.” It's like everything is definitely possible.
Ben: My heart is truly warm. Thank you.
Is there some philosophical underpinning around the Plasma security designs and how Layer 2s are going to work? One of the ultimate signs that something awesome has happened is that it sparks a debate in the community about security models. To me that basically is always a sign that the boundaries have been pushed forward. When there's something going on that has nuance and that is worthy of discussion and education, usually it means something exciting has happened.
I feel like we haven't really dove into Plasma as a Layer 2 security model design structure. I'm just curious about your takes on that. I have thoughts from the OG Plasma days and I'm curious for your take on it all.
Defining Plasma Mode
tdot: So I want to go over what Plama Mode is, and what it means exactly. There's a new OP Stack feature that we are the core developers of, which is experimental and incorporates one aspect of Plasma, which is offchain data availability.
We called it Plasma because it's advancing this idea that the input data is stored offchain. Instead of using L1 DA, you're storing it on any storage service, like AWS or IPFS. And then you have to essentially watch that the data is available. So at least one person needs to check that the data that the batcher submits is available.
If the data becomes unavailable for whatever reason, the protocol enables users to force exit within seven days. It is still missing some parts still in development, such as fault proofs that are coming out really soon, and permissionless commitments as well. Users can automatically verify data availability using Sentinel. If data becomes unavailable, you have to challenge this on L1.
And if data becomes unavailable, you have to challenge to essentially either force the data to be online or the data to be reorged, so that you can withdraw your funds and exit the chain. So at this stage, these components are not fully deployed. And so we definitely want to highlight that there is a path towards kind of like getting to that full to that scenario being completely permissionless and accessible to people.
There are some assumptions as well around the cost of what it would take for a user to challenge the data in order to withdraw. These things are still being defined and we're still optimizing these items so eventually they are cheaper and more accessible. There's a roadmap for this that we're working on. This is all distinct from the OP Stack roadmap for deploying fraud proofs and decentralizing the sequencer.
One of the issues with kind of this protocol is the Fisherman’s Dilemma, which is this idea where you need one honest “fisherman” to be online at all times because if nobody's online then you don't know that the data has become unavailable and you will not withdraw your funds during the the withdrawal window and essentially the chain could be attacked by whoever the operator is.
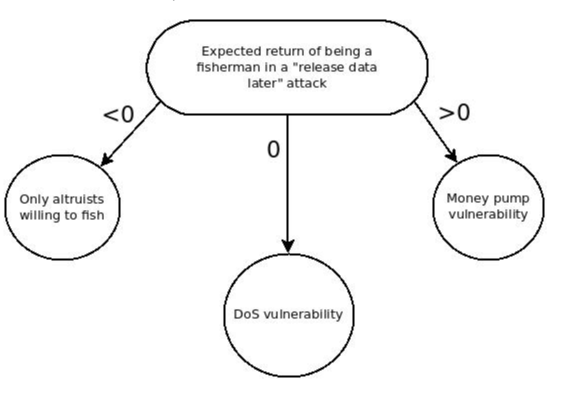 An illustration of the Fisherman's Dilemma
An illustration of the Fisherman's Dilemma
You have a bunch of ways that you can resolve this. You can incentivize people to stay online, you can create a strong community, you can make sure that users and stakeholders that have a lot of skin in the game, such as people who run bridges, or who are liquidity providers, and have skin in the game, stay online and make sure that the chain and operator remains honest. These users who we’d expect to stay online and challenge things if things go down But obviously the conversation is still interesting because there's ways that you can solve the dilemma and there's still a lot of work to be done to make this accessible to anyone and to make sure that users keep taking care of the chain.
Ben: What is a Layer 2? It's using Layer 1 more efficiently. The classic analogy here is, “You don't go to court to cash a check, you go to court when the check bounces.” And that's kind of like the fundamental design philosophy behind these optimistic systems and how we thought about roll-ups: using the chain more efficiently. By using L1 only when there's a dispute, it is going to allow you to squeeze more throughput in total out of the chain. I think this continues to be a great analogy for what Plasma Mode is doing. What Plasma Mode basically does is it extends beyond the notion of a rollup where you're going to court to dispute what the correct withdrawals are. In Plasma, you can also go to court to request that the data of transactions itself be made available.
And I think this is going to be a very, very, very powerful tool, because by accomplishing that, you've used the Layer 1 more efficiently, and you can put more data through the Layer 2 systems than you otherwise would be able to, and in a much cheaper cost regime than you would if it were just rollups. So that is super, super exciting. And I think the more exciting thing is that it allows you to basically improve over the status quo of what you could do if it wasn't there.
It's not perfect. There's the Fisherman's Dilemma, and that imposes some fundamental requirements on how this goes down. Most fundamentally, the exciting thing about Plasma, in comparison to other Alt DA systems, is you basically go from a safety trade-off to a liveness trade-off.
In other systems, you don't have the ability to go to court over what the data is. The data is just assumed to be there. And what that means is that you can have a situation where if the data isn't really there, you don't have sufficient evidence to prove the state of affairs in court, and you're out of luck. If you compare that to Plasma Mode, it makes a great trade off where it says, okay, by adding a new form of challenge, instead of the data going down, and everyone being out of luck, instead, you basically allow the community to go ahead and pay a fee to cover that data being posted to L1.
And while that dispute is in check, you might not know the state of the chain. That is true, but it's much better to make a liveness trade-off, where there might be a period of time where you don't know the state of the chain, than a safety trade-off, where you don't know if the chain's withdrawals are even valid, and you might allow somebody to commit an invalid withdrawal. So, that's how I think about Plasma Mode.
It's extending this notion of, “Don't go to court to cash a check, go to court when the check bounces,” and using it to improve the trade-offs that you make when you use alt-DA, So that instead of there being circumstances where the funds can be lost, you go to circumstances where the state of the chain is unknown for a little bit and users have to pay for the data to be published. And I think that's a super exciting tradeoff to have on the table.
tdot: I think there was a danger when we adopted the word Plasma: the baggage it has. The problem with it is the definition. When we announced Plasma Mode and deployed it to mainnet, I think a lot of people kind of assumed that it would be pretty much what Vitalik and others have described in their posts.
At the end of the day, this is still the OP Stack. When we brought these Plasma-like properties to the OP Stack, we didn't redesign the OP Stack. We still have the security assumptions of the OP Stack and then on top of this add off-chain DA. What we took from Plasma is the idea that you can challenge data and verify that data is available, and if data is not available you can force the DA provider to submit it on chain or you can re-org out the data so that you can exit. The security assumption is that you are able to force exit or withdraw no matter what, even if the chain operator or the DA provider becomes malicious.
There's a lot of moving parts to guarantee this scenario. Our idea was to guarantee the minimum, and build on top of some of the OP Stack guarantees and gradually get to this point where we can progressively decentralize and progressively bring in these guarantees. We already have all these frameworks for evaluating the security of rollups, established by folks like L2Beat, which are extremely useful for the community.
But Plasma itself doesn't really fit in that model. The problem is if you're trying to fit Plasma Mode exactly into the same framework as a rollup, it doesn't really feel like it fits in all the stages.
We still have to implement some of these things. And so that's why there is clarity that is needed in terms of figuring out what is exactly the roadmap and how to implement it. And I think these things are still getting properly defined. And I think it's cool that everybody can have the conversation together to figure out what these things mean and come up with definitions together.
Ben: Yeah, I super agree with that. There's a state of affairs of getting things running in terms of fault proofs and so on. You hit the nail on the head, though, that the Plasma security models need a new framework that is distinct from rollups. I think if you look at the context, fundamentally, there is no alternative, if you are bullish enough on scaling Ethereum you just require alternate data availability sources.
The reality is that rollups have very strong trade-offs. They're simpler to build. This is why the scaling community started by building them. But the reality is that if you want a truly horizontally scalable blockchain system, you cannot be constrained by the data throughput of L1. And if you're only using rollups, you’ll be constrained. So once you understand that the starting point is to bring blockchains to a global scale, you need an alternative data availability solution.
I mentioned before how Plasma is effectively the best we can do for Alt DA L2s, but there are tradeoffs. We need to communicate those clearly–if this data availability provider goes down, then funds are lost. But for Plasma, we actually need to communicate, “Okay, if this data availability layer goes down, now the users need to pay for L1 publishing in a way that they will not be recuperated.” To understand the security model of a Plasma, you'll say, “Okay, this is the DA provider, this DA provider could go down and cost X dollars per day for the community to keep the system secure.”
And then maybe you multiply that times the exit window and you say, “Okay, in the case of a malicious DA provider, there's going to be a net cost of X dollars, which basically is the cost to perform these challenges until people can get their funds out.” I think that's going to be very nuanced. There will be a lot of discussion of trade-offs there. You can obviously have more sophisticated sources of DA, which increases the cost of the attack and decreases the likelihood of having to burn that net cost.
At the same time, it increases the cost of the system. So ultimately, I think that what we really need to do as the stewards of this technology is to lay those trade-offs out super explicitly. I think that you guys are right on the money in terms of your philosophy that there are naturally going to be DA providers that have a very reasonable incentive not to put us in this Fisherman’s Dilemma situation because at the end of the day, they couldn't even take the money out. They could just cause other folks to burn some funds. It's probably one of my favorite philosophical L2 scaling debates of all time. It's kind of the OG one–before we realized “we probably need to do that eventually, but we can sidestep this whole issue by posting data to L1.” So it's exciting to see it back in the public eye.
And I think in the next year, we'll start to really have increased understanding from the community.
 Coming full-circle, from OPCraft to Biomes on Redstone
Coming full-circle, from OPCraft to Biomes on Redstone
Standardizing Chains and Heading into the Future
tdot: We need better tools for people to verify the chain and keep guaranteeing and checking that data is available, then validating and checking the output proposed and checking all these things just to know that by default you're going to have at least one person that's verifying.
The more people verifying, the greater the value of the chain. So if we make it cheap and easy for people to run these verifiers, then you can pool community resources and figure out ways where you can make sure that there's always someone to challenge and there's always someone to verify things. It’s a core thread of making things more secure and more decentralized.
It's really cool that we can all collaborate on these things together. It gets more eyes on the protocol, more ideas, more conversation, like more testing. I think Plasma Mode is going to be run by others. There's going to be way more situations where people are going to discover and experience it. And so running your protocol and knowing that more people are running your protocol just adds so much more review and battle testing to it. In the end, we're going to figure out some solutions that are going to be extremely robust. So definitely also super excited about this. If we had gone and baked this protocol in our little corner, it would be such a different experience.
Ben: So that's why it's a good way to figure it out. One of the things that we realized was that standardization was going to be super important to the OP Stack. We need to offer a way for people to run these chains that is uniform, understandable by all, and has the security properties that they claim to have. Because one of the tricky things is that an outside team can make something that seems like a very innocent change and actually have dramatic downstream impacts on the security of the system, or the performance of the system, or the behavior of the system generally. From our perspective, standardization is a powerful thing. Not only will we have that community discussion, but then out of that community discussion will birth a set of options that people can responsibly run and communicate.
It's an incredible public good that L2Beat provides in giving security models. It's also very bespoke right now and kind of one-off. And what we need to get into is a state of affairs where actually in compiling or deploying your version of the OP stack, you put it in Plasma Mode and instead the stack prints out the security assumptions that you’ve taken on. So it's critical to standardize. You're right. If everybody were to go build this in a little silo off on the side and there wasn't one upstream standard implementation, these problems would reign a thousand times over.
tdot: It's also really cool to already have it running with stakeholders and apps because once you're in production you really can have even more educated conversation about what people care about. You actually know the people who are running on the chain, who are deploying, and you can go talk to them and ask “What do you expect, What do you need, How much are you willing to spend on this, or is this too expensive, Is the chain too cheap?” You can really have real world feedback instead of going into these endless discussions where you just can't really know until you run it and you experience it.
And that's the thing about game theory. You have to test things out in the real world. Otherwise, you have no idea. You can speculate on things, but you always get punched in the face. So I think the way you just go about it is you have to go iterate in a reasonably safe environment and just test experiments. That's really cool as well. It's like being able to have different security layers; you have chains that have higher standards of security, and then you go up to the bleeding edge, like crazy tech stuff on the edge to experiment with things.
Things are going to be cheaper, more performant, but it's a little riskier. And you just go and experiment with things. And from there, you’re driving innovation. And so there's a risk and reward as well for being the first people on these chains that are pushing the limit. That's something that we're spending a lot of time thinking about this year as well.
Ben: The Collective as well is understanding the contribution paths. I think you alluded to it very well. You basically have a trade-off to make between battle testing improvements in the wild and running chains that are secure and already battle-tested and known. And ultimately, we basically see the OP Stack as the open-source facilitator of that process, where people at the edges are building incredible things, they're proving that they work, and then they're getting upstreamed into the standards so that everyone can take advantage of them.
So it's very much the positive-sum, open-source, grow-the-pie philosophy. You're totally right. There are trade-offs that have to be made to push the envelope. And it's critical that we build the processes that allow you to take those envelope-pushing moments, like the release of Redstone, and be able to simultaneously solve for having agility and making awesome improvements to the Ethereum scaling landscape, which has probably another decade of life to go, and simultaneously be able to take those make them well-defined experiments and then be able to merge them into the standard once they've been proven out.
We’re really excited to be on that journey with y'all.
tdot: I think having these differences while still being able to be part of the Superchain is also really cool in terms of sharing revenue and incentivizing people to go experiment and deploy on these new chains while still benefiting the whole community and benefiting all the different implementations.
It’s also really cool to have a model like this instead of people kind of running forks in their corners. It’s hard to keep track of and then you make security mistakes. Whereas here, you have this framework where you can validate and check what people are doing. So that's also definitely a huge benefit. I think it naturally arrived at this. Seeing it evolve over the last year has been really fascinating.
Ben: Positive sum, baby, we gotta keep pushing the envelope. What I think is amazing is that ultimately, the right way to view this in the long term is as an extension to Ethereum itself. One of the really cool things that's happened in the past year is the rollup improvement process has come online, which basically, basically sits at the intersection of Layer 1 core developers and Layer 2 core developers, such as ourselves and yourselves.
I think what we'll start to see more of that we haven't seen a ton of yet is a world where even the ultimate central standard for that becomes Layer 1 Ethereum itself. I think we'll start seeing Layer 2’s adopt major EIPs that folks really are eager to get on Layer 1. And Layer 2 is basically a great test bed where it starts at like some random fork off on the side, then we merge it into the OP stack, and we put it out there.
Eventually it lands on Layer 1 and everyone rejoices. So it's going to be really cool. It's kind of like making an organism out of Ethereum and the Ethereum code base is the DNA.
tdot: That makes sense as well.
Ben: Yeah, it's awesome. I mean, turning back to the amazing chain that is Redstone though, tdot, what are you excited about going on in Redstone land right now?
tdot: Oh man, we have the most awesome apps. Honestly, I'm always blown away. I just keep playing This Cursed Machine and it's just like the most insane app possible. It is just crazy that this is running right now on Redstone. It's really awesome when people unleash their creativity and create something that was just like never done before.
Ben: Is it the first onchain horror game? I don't know if I've ever seen anything like This Cursed Machine before.
tdot: I don't know. It's a good question. I think putting these experiences onchain just really pushes you. I definitely enjoy when people kind of like bring in these new games that are completely crazy instead of like porting some existing games on-chain.
Ben: I'm kind of loath to do the classic VC analogy to early internet days, but I do feel like it's totally a thing that like all of the autonomous worlds on Redstone have really been leading the charge on. There’s the analogy that when the internet first came about, the intuition was like, take the thing that we already have and put it on the internet, you know, like newspapers, make them digital.
And the real innovation came about when you realized how to use the new features of that system. Actually a newspaper on the internet isn't as valuable as everybody having their own mini newspaper that's 240 characters long. And that to me is very much a space of innovation that is going down in Redstone. The community right now is pushing the envelope of what the heck are on-chain games and worlds for and how can we push them.
tdot: Yeah, we’re super excited. It definitely attracts super dynamic communities where you're just pushing ideas to the extreme. It's a nice change from a more speculative mindset and things like that. I feel like just the idea of playing games with friends is also very wholesome and attracts really, really nice people.
It's time for the toy, baby. I think we're not ready for all the new stuff that's going to come out. So definitely excited about this.
Ben: Plasma's back, baby. Long live Plasma.
tdot: We’re super excited to keep building stuff. We're just getting started.